SVM Result: Test Dataset
SVM Result: Test Dataset¶
In this section, we will see the performance of the trained SVM on the test dataset.
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.metrics import classification_report
import numpy as np
import pandas as pd
import pickle
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 1
----> 1 from sklearn.svm import SVC
2 import matplotlib.pyplot as plt
3 from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
ModuleNotFoundError: No module named 'sklearn'
feature_matrix_test = pd.read_csv("./data/final_feature_matrix_test.csv", index_col = 0)
X = feature_matrix_test.drop("fraudulent", axis = 1).values
y = feature_matrix_test.fraudulent.values
with open('./pickle/svm_model.pkl', 'rb') as f:
svm_model = pickle.load(f)
y_predict =svm_model.predict(X)
cm = confusion_matrix(y, y_predict, labels=svm_model.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=svm_model.classes_)
disp.plot()
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x276fc88bd30>
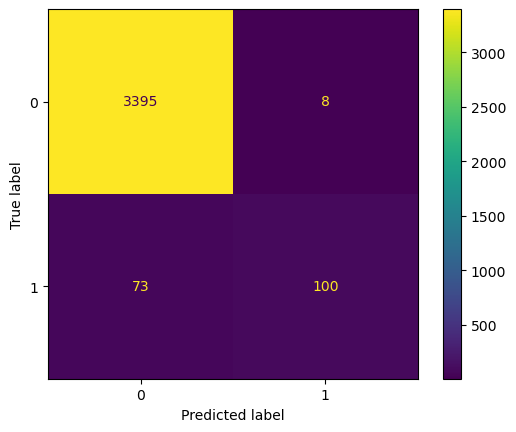
print(classification_report(y, y_predict))
precision recall f1-score support
0 0.98 1.00 0.99 3403
1 0.93 0.58 0.71 173
accuracy 0.98 3576
macro avg 0.95 0.79 0.85 3576
weighted avg 0.98 0.98 0.97 3576
The performance of SVM on the test set looks great! Compared to the SVM in the previous work, we have improved on both accuracy and recall rate. Especially there is quite an impressive improvement in the recall rate (30% to 58%), which implies another improvement in fixing the overfitting problem that arose in the previous work.